
Collective Communication Routines
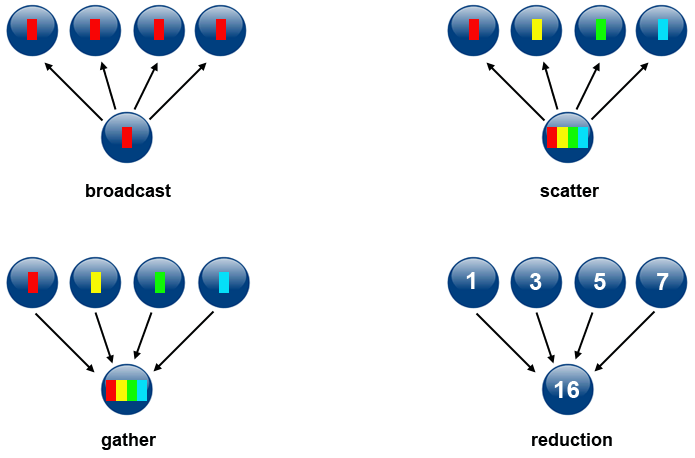
Types of Collective Operations:
- Synchronization - processes wait until all members of the group have reached the synchronization point.
- Data Movement - broadcast, scatter/gather, all to all.
- Collective Computation (reductions) - one member of the group collects data from the other members and performs an operation (min, max, add, multiply, etc.) on that data.
Scope:
Collective communication routines must involve all processes within the scope of a communicator. All processes are by default, members in the communicator MPI_COMM_WORLD. Additional communicators can be defined by the programmer. See the Group and Communicator Management Routines section for details.
Unexpected behavior, including program failure, can occur if even one task in the communicator doesn’t participate.
It is the programmer’s responsibility to ensure that all processes within a communicator participate in any collective operations.
Programming Considerations and Restrictions:
Collective communication routines do not take message tag arguments.
Collective operations within subsets of processes are accomplished by first partitioning the subsets into new groups and then attaching the new groups to new communicators (discussed in the Group and Communicator Management Routines section).
Can only be used with MPI predefined datatypes - not with MPI Derived Data Types.
MPI-2 extended most collective operations to allow data movement between intercommunicators (not covered here).
With MPI-3, collective operations can be blocking or non-blocking. Only blocking operations are covered in this tutorial.
Collective Communication Routines
Synchronization operation. Creates a barrier synchronization in a group. Each task, when reaching the MPI_Barrier call, blocks until all tasks in the group reach the same MPI_Barrier call. Then all tasks are free to proceed.
MPI_Barrier (comm)
MPI_BARRIER (comm,ierr)
Data movement operation. Broadcasts (sends) a message from the process with rank “root” to all other processes in the group. Diagram here
MPI_Bcast (&buffer,count,datatype,root,comm)
MPI_BCAST (buffer,count,datatype,root,comm,ierr)
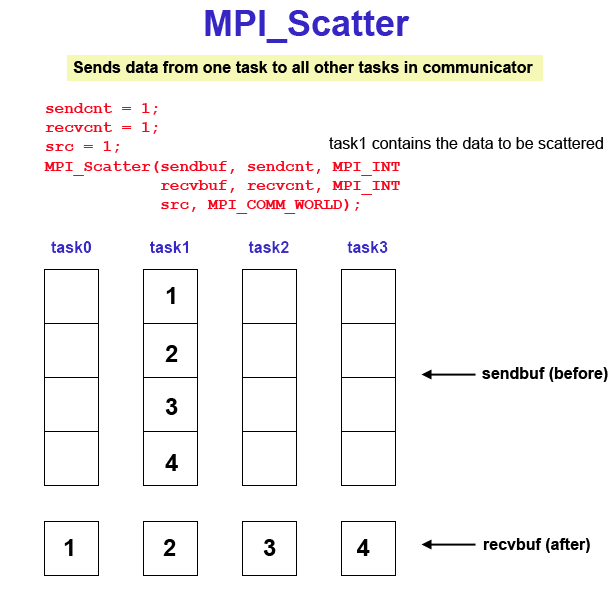
Data movement operation. Distributes distinct messages from a single source task to each task in the group. Diagram here
MPI_Scatter (&sendbuf,sendcnt,sendtype,&recvbuf,recvcnt,recvtype,root,comm)
MPI_SCATTER (sendbuf,sendcnt,sendtype,recvbuf,recvcnt,recvtype,root,comm,ierr)
Data movement operation. Gathers distinct messages from each task in the group to a single destination task. This routine is the reverse operation of MPI_Scatter. Diagram here
MPI_Gather (&sendbuf,sendcnt,sendtype,&recvbuf,recvcount,recvtype,root,comm)
MPI_GATHER (sendbuf,sendcnt,sendtype,recvbuf,recvcount,recvtype,root,comm,ierr)
Data movement operation. Concatenation of data to all tasks in a group. Each task in the group, in effect, performs a one-to-all broadcasting operation within the group. Diagram here
MPI_Allgather (&sendbuf,sendcount,sendtype,&recvbuf,recvcount,recvtype,comm)
MPI_ALLGATHER (sendbuf,sendcount,sendtype,recvbuf,recvcount,recvtype,comm,info)
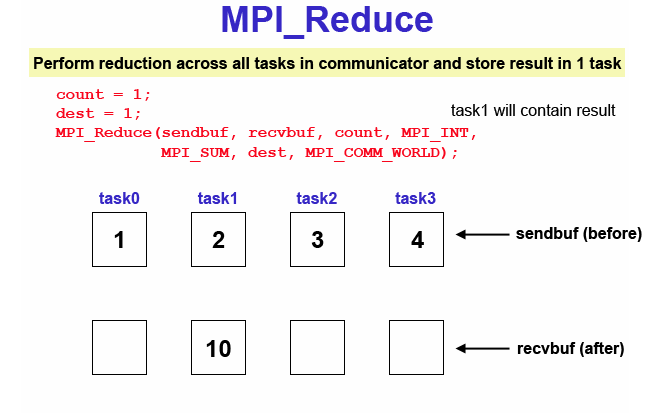
Collective computation operation. Applies a reduction operation on all tasks in the group and places the result in one task. Diagram here
MPI_Reduce (&sendbuf,&recvbuf,count,datatype,op,root,comm)
MPI_REDUCE (sendbuf,recvbuf,count,datatype,op,root,comm,ierr)
The predefined MPI reduction operations appear below. Users can also define their own reduction functions by using the MPI_Op_create routine.
Note from the MPI_Reduce man page: The operation is always assumed to be associative. All predefined operations are also assumed to be commutative. Users may define operations that are assumed to be associative, but not commutative. The “canonical” evaluation order of a reduction is determined by the ranks of the processes in the group. However, the implementation can take advantage of associativity, or associativity and commutativity in order to change the order of evaluation. This may change the result of the reduction for operations that are not strictly associative and commutative, such as floating point addition. [Advice to implementors] It is strongly recommended that MPI_REDUCE be implemented so that the same result be obtained whenever the function is applied on the same arguments, appearing in the same order. Note that this may prevent optimizations that take advantage of the physical location of processors. [End of advice to implementors]
Collective computation operation + data movement. Applies a reduction operation and places the result in all tasks in the group. This is equivalent to an MPI_Reduce followed by an MPI_Bcast. Diagram here
MPI_Allreduce (&sendbuf,&recvbuf,count,datatype,op,comm)
MPI_ALLREDUCE (sendbuf,recvbuf,count,datatype,op,comm,ierr)
Collective computation operation + data movement. First does an element-wise reduction on a vector across all tasks in the group. Next, the result vector is split into disjoint segments and distributed across the tasks. This is equivalent to an MPI_Reduce followed by an MPI_Scatter operation. Diagram here
MPI_Reduce_scatter (&sendbuf,&recvbuf,recvcount,datatype,op,comm)
MPI_REDUCE_SCATTER (sendbuf,recvbuf,recvcount,datatype,op,comm,ierr)
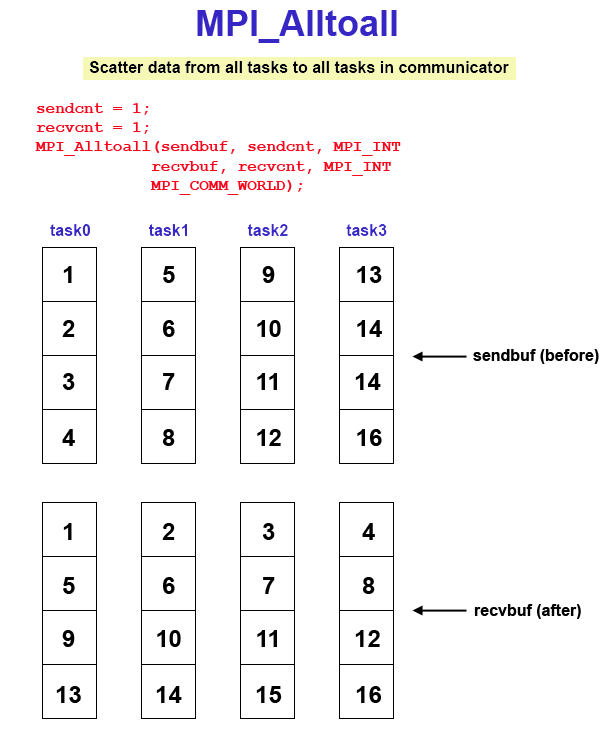
Data movement operation. Each task in a group performs a scatter operation, sending a distinct message to all the tasks in the group in order by index. Diagram here
MPI_Alltoall (&sendbuf,sendcount,sendtype,&recvbuf,recvcnt,recvtype,comm)
MPI_ALLTOALL (sendbuf,sendcount,sendtype,recvbuf,recvcnt,recvtype,comm,ierr)
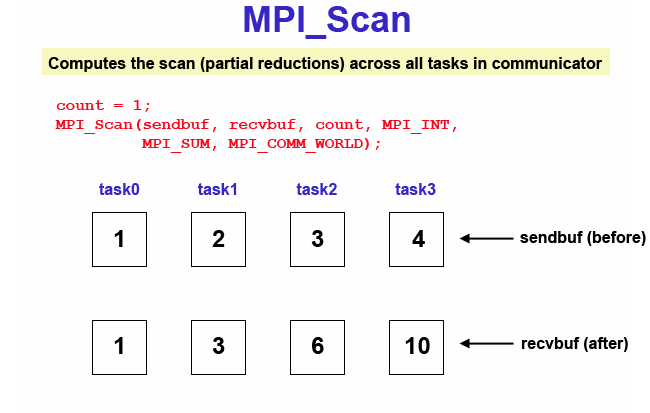
Performs a scan operation with respect to a reduction operation across a task group. Diagram here
MPI_Scan (&sendbuf,&recvbuf,count,datatype,op,comm)
MPI_SCAN (sendbuf,recvbuf,count,datatype,op,comm,ierr)
Examples
C Language - Collective Communications Example
#include "mpi.h"
#include <stdio.h>
#define SIZE 4
main(int argc, char *argv[]) {
int numtasks, rank, sendcount, recvcount, source;
float sendbuf[SIZE][SIZE] = {
{1.0, 2.0, 3.0, 4.0},
{5.0, 6.0, 7.0, 8.0},
{9.0, 10.0, 11.0, 12.0},
{13.0, 14.0, 15.0, 16.0} };
float recvbuf[SIZE];
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
if (numtasks == SIZE) {
// define source task and elements to send/receive, then perform collective scatter
source = 1;
sendcount = SIZE;
recvcount = SIZE;
MPI_Scatter(sendbuf,sendcount,MPI_FLOAT,recvbuf,recvcount,
MPI_FLOAT,source,MPI_COMM_WORLD);
printf("rank= %d Results: %f %f %f %f\n",rank,recvbuf[0],
recvbuf[1],recvbuf[2],recvbuf[3]);
}
else
printf("Must specify %d processors. Terminating.\n",SIZE);
MPI_Finalize();
}
Fortran - Collective Communications Example
program scatter
include 'mpif.h'
integer SIZE
parameter(SIZE=4)
integer numtasks, rank, sendcount, recvcount, source, ierr
real*4 sendbuf(SIZE,SIZE), recvbuf(SIZE)
! Fortran stores this array in column major order, so the
! scatter will actually scatter columns, not rows.
data sendbuf /1.0, 2.0, 3.0, 4.0, &
5.0, 6.0, 7.0, 8.0, &
9.0, 10.0, 11.0, 12.0, &
13.0, 14.0, 15.0, 16.0 /
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
if (numtasks .eq. SIZE) then
! define source task and elements to send/receive, then perform collective scatter
source = 1
sendcount = SIZE
recvcount = SIZE
call MPI_SCATTER(sendbuf, sendcount, MPI_REAL, recvbuf, recvcount, MPI_REAL, &
source, MPI_COMM_WORLD, ierr)
print *, 'rank= ',rank,' Results: ',recvbuf
else
print *, 'Must specify',SIZE,' processors. Terminating.'
endif
call MPI_FINALIZE(ierr)
end
Sample program output:
rank= 0 Results: 1.000000 2.000000 3.000000 4.000000
rank= 1 Results: 5.000000 6.000000 7.000000 8.000000
rank= 2 Results: 9.000000 10.000000 11.000000 12.000000
rank= 3 Results: 13.000000 14.000000 15.000000 16.000000


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}