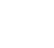Why Pthreads?
Pthreads Overview: Why Pthreads?
Lightweight:
When compared to processes, threads can be created and managed with much less overhead from the operating system.
For example, the following table compares timing results for the fork() subroutine and the pthread_create() subroutine. Timings reflect 50,000 process/thread creations, were performed with the time utility, and units are in seconds, no optimization flags.
Note: don’t expect the system and user times to add up to real time, because these are SMP systems with multiple CPUs/cores working on the problem at the same time. At best, these are approximations run on local machines, past and present.
Efficient Communications/Data Exchange:
Pthreads can be used to achieve optimum performance in a high performance computing environment. In particular, if an application is using MPI for on-node communications, there is a potential that performance could be improved by using Pthreads instead.
MPI libraries usually implement on-node task communication via shared memory, which involves at least one memory copy operation (process to process).
For Pthreads there is no intermediate memory copy required because threads share the same address space within a single process. There is no data transfer, per se. It can be as efficient as simply passing a pointer.
In the worst case scenario, Pthreads communications become more of a cache-to-CPU or memory-to-CPU bandwidth issue. These speeds are much higher than MPI shared memory communications.
Other Common Reasons:
Threaded applications offer potential performance gains and practical advantages over non-threaded applications in several other ways:
- Overlapping CPU work with I/O: For example, a program may have sections where it is performing a long I/O operation. While one thread is waiting for an I/O system call to complete, CPU intensive work can be performed by other threads.
- Priority/real-time scheduling: tasks which are more important can be scheduled to supersede or interrupt lower priority tasks.
- Asynchronous event handling: tasks which service events of indeterminate frequency and duration can be interleaved. For example, a web server can both transfer data from previous requests and manage the arrival of new requests.
A perfect example is the typical web browser, where many tasks varying in priority should be happening at the same time, and thus can be interleaved.
Another good example is a modern operating system, which makes extensive use of threads. A screenshot of the MS Windows OS and applications using threads is shown below.